Learning from Ryan Howard’s Slump
As most of us know, the Phillies are having a forgettable 2015 season. Their first baseman, Ryan Howard, recently had a “0 for 35” slump. What does that say about Howard’s batting ability this season? We will first describe a traditional “frequentist” calculation, and then describe a Bayesian simulation approach that more directly addresses the question about Howard’s ability.
A Traditional Calculation
A standard way to make sense of an “0 for 35” is to make some assumption about Howard’s batting ability and then compute the probability of this batting event if that model is true.
Let 



Learning About Howard’s Batting Ability by Bayes’ Rule
Although this calculation is interesting, it really is addressing the wrong question. We observe Howard’s 0 for 35 — what does that tell us about Howard’s true batting average? We describe a simple Bayesian procedure that describes how we can learn about a player’s batting ability from this streak data.
Initial Beliefs about P
What do we initially believe about Howard’s true batting averages

Updating Beliefs with Data
So suppose one observes a player’s hitting slump. First we suppose that one has a “0 for 15” slump during a 500 AB season. What does that tell us about the player’s hitting ability?
We do a so-called “model-data” simulation to answer this question.
- First we simulate a possible value of
- For this value of
We repeat this simulation a large number of times. To get the updated (posterior) probabilities about the batter’s abiity, we collect only the values of

What is interesting is that this density is pretty flat from 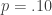
But Howard had a “0 for 35” slump. We repeat this simulation to see what we learn from a “0 for 35 or greater” slump.

Here we see that we have learned much more about a batter’s ability from this long slump. His true batting ability is more likely to be in the (.10, .15) range.
Closing Comments
- All of the R code for this exercise can be found here.
- This is a general way of implementing Bayes’ rule that can be used to revise opinion on the basis of different types of data. I coauthored a paper (with Patricia Williamson) which illustrates the model/data simulation approach. By using simulation, we don’t have to worry about the exact form of the likelihood.
- One nice feature of this approach is that it controls for multiplicity. By focusing only on the selected “0 for 35” data, one introduces a selection bias. Instead, we are considering the data “0 for 35 sometime during a full season of hitting”. (It is more likely for a player to go through a slump sometime during the season than to go through a slump on specific days.)

Recent Comments