Multilevel Modeling of OBP Trajectories
Introduction
A general problem in sabermetrics is to understand the patterns of career trajectories of baseball players. Specifically, when does a baseball player achieve peak performance? Phil Birbaum recently had a post in his Sabermetric Research blog where he talks about using regression models to understand trajectory patterns. This is a topic that I’ve played around with (probably too much!) for many years. Here’s my latest attempt to describe the use of Bayesian multilevel models to understand these trajectories. Monika Hu and I recently completed an undergraduate text on Bayesian modeling and this application is one of the case studies in our last chapter. I think this Bayesian modeling approach is one of the most attractive ways of learning about trajectories of professional athletes. Also, this will give me an opportunity to show the ease of fitting these multilevel models using Stan, the current “fast” algorithm for simulating Bayesian models by Markov chain Monte Carlo.
The Wrong Way to Look at Aging Data
Suppose I am interested in aging patterns of on-base performance. I collect all of the players born in 1974 who had at least 1000 at-bats. So I have a data frame for 30 players with variables Player, OB, PA, and Age — I have the on-base records (that is, the counts of OB events and PA) for each player each season. The wrong way to explore aging is to simply find the cumulative on-base percentage for each age producing the following graph. This seems to indicate that the peak age for on-base performance for this group of players is 26.

But actually the graph below where I distinguish the points by the players is a better representation of this data.

Our simplistic “OBP by Age” graph ignored the fact that players have different career lengths and these OBP averages for each age are taken over different groups of players. Bill James in one of his early Baseball Abstracts cautioned us from performing this naive aging analysis. It results in a biased estimate of peak performance. (Actually, in a quick search, I see that Bill James has a recent article on aging patterns, showing that Bill, like me, remains interested in this aging problem.)
Derek Jeter’s OBP Trajectory
We have to look at the individual career trajectories. Let’s consider Derek Jeter, one of the “born in 1974” players currently being considered for the Hall of Fame. (Will Jeter get a unanimous vote to get in the HOF?) Below I have graphed Derek Jeter’s OBP against age for all of the seasons of his career. I fit the quadratic logistic model

and show the fit as a red line on the scatterplot. Here I think one gets a reasonable view of Jeter’s career trajectory. He started playing at a relatively high level, peaked around age 29 and his on-base percentage performance decreased gradually until his retirement at age 40.

The Problem: Individual Fits Can be Crummy
The problem is that this quadratic regression model doesn’t always work well. To demonstrate this, I collected the career on-base percentage data for all players who were born in 1974 (like Jeter) and had at least 1000 career at-bats. (There were 30 players in this group.) I fit this logistic quadratic model to the (Age, OBP) data for each player. Below I graph the 30 individual logistic fits. Some of these fits like the one for Jeter are reasonable, but other fits are strange. Some of these fits don’t have a clear “down-up-down” pattern that you would expect. Some of these fits have dramatic rises and falls which are questionable. One issue that particular good or poor years can have dramatic effects on the fit for an individual player.

What Can We Do?
This is a basic problem. We want to learn about how individual players age, but these individual player fits can be problematic. In order to make sense of this data, we need to combine this data in some way. One thought is to assume that each player has the same peak age, say 29, and then estimate trajectories that are based on this assumption. Or maybe assume that everyone’s trajectory rises and falls in the same way. But this is not realistic — we know that players peak at different ages and have different patterns of growth and decline. The challenge is to “partially pool” the data across players in such a way to still treat the individual trajectories as separate entities to estimate.
Multilevel Modeling to the Rescue
There is a natural Bayesian way to treat this problem. One assumes that each player has a unique “true” trajectory described by a quadratic curve. One can describe the ith player’s trajectory by the parameters 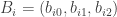



Multilevel Modelling Gives Reasonable Fits
We fit this model by simulation. Basically, we use the Stan algorithm that explores the high-dimension posterior probability distribution for all of the unknown parameters. This is a relatively new Markov chain Monte Carlo (MCMC) algorithm and there are nice packages available for using this Stan algorithm for fitting multilevel regression models like this one. Stan was specifically written to facilitate the sampling of multilevel models for many parameters. Here I used the brms package — this single line of code shown below will accomplish this MCMC fitting of these 30 trajectories by this multilevel model. The output of this fit is a large matrix of simulated draws from the posterior probability distribution. (In this code, OB is the number of on-base events, PA is plate appearances, AgeD is the deviation of the player’s age from 30 and Player is the player number.)

Below I display the (posterior mean) multilevel trajectory fits for the 30 players using red lines — the blue lines in the background are the individual fits that we saw earlier. What we see is the the multilevel fits shrink the individual fits towards an average fit. For a player like Derek Jeter, the multilevel fit will only adjust the individual fit a small amount — this makes sense since Jeter had a long career and we have a good handle on his trajectory from his data. For another player with a short career, we don’t understand his trajectory very well, and his individual trajectory fit will be strongly adjusted towards the average trajectory.

When Do Players Peak?
The individual trajectory fits can give relatively poor estimates at player’s peak age — that is the age when he achieves peak OBP performance. When one fits this multilevel model, one partially pools the data for the 30 players and one gets improved estimates at peak age. Below I show the estimates at the peak ages for the 30 players using the individual quadratic fits (bottom) and the multilevel model fits (top). Note that the individual estimates at peak ages are adjusted in the multilevel modeling towards the average. The takeaway message is that most players tend to peak (with respect to on-base performance) between 28 to 30 and a few players had early peak ages.

Some Closing Comments
- How do the multilevel estimates behave? It is interesting to compare the individual and multilevel trajectory fits in the above graph. Looking at the collection of red lines, they have different levels (high and low), but the shapes of the curvatures of the multilevel trajectories are similar. This tells me that player clearly differ in their on-base abilities, but OBP is a particular baseball talent that shows modest change during a player’s career. If a team signs someone with a good ability to get on base, then I would predict that this player’s OBP performance would not age badly. (Remember Bill Beame in Moneyball wanted to recruit players with good on-base performance — he didn’t appear to worry about the aging effect of these players.)
- Things to explore. I did a toy example here to illustrate how the modeling works. But I think this is a powerful method for understanding trajectories of ballplayers. Players have different talents (like slugging, getting on base, fielding) and each of these talents may have unique career trajectories. It would be interesting to focus on players who play a specific position and fit a multilevel model on the trajectories of these players. It is even possible to consider players with a range of fielding positions and use fielding position as a covariate to learn how aging of different types of players differ.
- Want to learn more? This method is a generalization of the problem of simultaneously estimating a collection of batting averages. I have a number of posts that talk about career trajectories and/or illustrate Bayesian multilevel modeling in different contexts. Here are some links:
- Here is one of my more popular posts where I use loess smoothing of trajectories to learn about peak age performance:
https://baseballwithr.wordpress.com/2017/05/08/what-age-do-baseball-players-peak/
- Here is a post on “shrinking batting averages”. https://baseballwithr.wordpress.com/2014/01/06/shrinking-batting-averages/
- Here I illustrate multilevel modeling for data similar to Efron and Morris’ famous baseball study: https://baseballwithr.wordpress.com/2016/02/15/revisiting-efron-and-morriss-baseball-study/
- Here is one of my old technical reports on career trajectories in baseball: http://www-math.bgsu.edu/~albert/papers/career_trajectory.pdf
- Here’s the link to that player trajectory case study in our new Bayesian modeling text: https://bayesball.github.io/BOOK/case-studies.html#career-trajectories
- Here is one of my more popular posts where I use loess smoothing of trajectories to learn about peak age performance:
- Got R Code? Yes, all of the R code for this exercise can be found at my Github Gist site. This will allow you to get all of the data and run the multilevel analysis. You can look at different groups of players by adjusting the birthday and minimum number of career AB.

Recent Comments