Bayesian Tutorial 4: Multilevel Modeling of Player Count Effects
Introduction
This post is the last one in my Bayesian Tutorial series. In part I and part II of this series, I illustrated some basic components of Bayesian thinking in the context of a nonlinear regression model. In part III of this series, I introduced some situational hitting data, setting the stage for this post’s discussion of Bayesian multilevel models. Multilevel modeling is one of the big Bayesian success stories and it is a great way of implementing a regression model when there is a natural grouping of the data. By the way, the Economist currently has forecasts for the US 2020 Presidential election that are based on the use of dynamic Bayesian multilevel models on polling data.
Let’s review the basic situational data problem introduced in last week’s post. We’re interested in learning about the hitter’s advantage when he has a favorable count. Here we are going to compare “neutral” counts (0-0, 1-0, 1-1, 2-1, 3-2) with “behind” counts (0-1, 0-2, 1-2, 2-2) and see how a batter’s expected wOBA improves as he is in a neutral count as opposed to being behind in the count. (I decided on not using the “ahead” counts due to the small sample sizes.). We’re going to use a simple regression model to make this comparison and we’ll contrast three approaches:
- Pool the Data. We can assume that all batters are the same with respect to their BABIP ability and their ability to take advantage of the favorable count situation. Then we’d fit a single regression model to all of the hitting data for a specific season.
- Individual Estimates. On the other extreme, we can assume that batters differ with respect to their hitting ability and also their ability to take advantage of the count situation. Then we would fit separate regression models for all of the “regular” hitters in a season.
- Multilevel Model Estimates. Last, we’ll consider a so-called “varying intercepts, varying slopes” multilevel model which states that the individual regression parameters come from a common prior distribution with unknown parameters. We’ll illustrate a “quick fit” to this multilevel model and show that we obtain better estimates at player hitting abilities and their abilities to take advantage of the count. We’ll learn about the variation in the players’ abilities and in the players’ situational abilities.
A Simple Regression Model
We focus how the expected wOBA depends on the count, focusing on the comparison between the neutral count and behind in the count situations.
Let y denote the expected wOBA. Define the “effect” to be 0.5 if the batter is in a neutral count and −0.5 if the batter is behind in the count. We assume that y is normal with mean μ and standard deviation σ where the mean response μ is written as
μ = 
In the neutral count, the mean is 



A Pooled Data Estimate
Suppose we consider the group of batters in the 2019 season who had at least 200 balls in play, the “regular” players. The pooled estimate would fit a regression model to all of the balls in play for these players. Interpreting the coefficients below for the lm() fit, we see 0.372 is an average expected wOBA and hitters tend to hit 0.046 better when they are in a neutral count as opposed to behind in the count. The line segment in the graph displays the “regression curve” corresponding to this pooled data estimate.
fit <- lm(estimated_woba_using_speedangle ~ effect,
data = sc_regular_2)
fit$coef
## (Intercept) effect
## 0.37196099 0.04550857

Individual Estimates
There are over 200 regular players in our dataset. We could instead do separate regression fits for all players, obtaining many sets of regression coefficients. I have displayed a random sample of 50 of these individual regression curves below. Looking at this graph, we see that many hitters do perform better in the neutral count state. But the size of improvement varies and actually some hitters hit worse when there is a neutral count. Honestly, I don’t believe that some hitters actually have a lower talent to hit when facing a neutral count compared to behind in the count.

A Multilevel Model and Quick Fit
I hope I’ve convinced you that both the pooled data fit and the individual regression fits are unsatisfactory. Here’s a multilevel model in this situation. Let 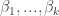
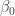


In this matrix, 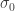
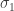

I could explain how to fit this complicated Bayesian model by using Stan. To save space and time I present a quick fit of this “random effects” model by using the lmer() function in the lme4 package. (This essentially fits this model by finding point estimates of the unknown parameters at the 2nd stage of the multilevel prior.). Here is the R syntax for fitting this model. The (1 + effect | player_name) indicates that we are fitting a varying intercept and varying slope model.
newfit <- lmer(estimated_woba_using_speedangle ~
effect + (1 + effect | player_name),
data = sc_regular_2)
summary(newfit)
I have pasted a summary of the multilevel fit below — let’s focus on the circled parts of the output.
- The section circled in blue gives overall slope and intercept estimates. Overall, the mean wOBA value is 0.372 and the advantage of being in the neutral count is 0.43. These are approximately the same values as the estimates we found in the pooled model.
- The section circled in red gives estimates at the components of the variance-covariance matrix

Performance
Also the lmer() fitting function provides estimates at the “random effects”, that is, the regression intercepts and slopes for the individual players. (I called these individual regression parameter vectors

The following graph is another way to look at these multilevel model estimates. The scatterplot displays the individual intercept and slope estimates (red) and the multilevel model estimates (blue) are placed on top. Note that many of the individual slope estimates (the 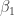

Wrapup
- Baseball folks are always fascinated with situational effects. For example, we see situational effects when players are platooned against specific pitchers. The managers are deciding that specific players won’t or will perform well in particular situations. When the managers are doing that, they are deciding that players have platoon talents. That is, the managers believe the observed situational effects correspond to real abilities and the current situational effects are predictive of future situational data.
- Also situational data is hard to understand since there is so much variability in these observed situational effects due to the small sample sizes. We saw this in our exploration of count effects — the count advantage from less favorable to more favorable situations was actually negative for some players in the 2019 season.
- Although people understand the difficulty in making sense of situational data, they aren’t sure what to do — what observed situational effects are real or luck-driven?
- Multilevel modeling is a very attractive way of making sense of situational data. Basically, the multilevel model estimates adjust the individual estimates towards a common value and the degree of adjustment depends on the particular situation. In our situation, the variation in individual count effects appears to be mainly luck-driven and the multilevel estimates shrink them heavily towards a constant value.
- All of the R work for these two posts on situational count data and multilevel modeling is contained in a Markdown file in my Gist Github site. If you have some Statcast data, you should be able to replicate my work.

Recent Comments