What is the Chance a Division Winner Will Decline the Following Season?
Introduction
In a couple of months, I will giving.a talk at the New England Symposium on Statistics in Sports reviewing Carl Morris’ contributions to statistical thinking in sports. In one of his review papers, Morris provides a nice baseball illustration of a Bayesian model explaining the regression to the mean phenomenon, the idea that extreme performances by teams or individuals tend to move to the average in the following season. Here I describe Morris’ example, use a Shiny app to illustrate the posterior and predictive calculations, and show that the results from this Bayesian model seem to agree with what happens in modern baseball competition.
The Model
Suppose a team wins their division in a particular season. What is the chance that they will decline in the following season? Let 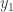
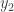
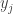




Constructing the Prior
Morris’ best guess is that this particular division-winning team is average which means that it would win half of its games in the long-run. Also he believes that it is unlikely that the team would win more than 60% of its games in the long run. So he assumes 



Bayesian Calculations
In this scenario, since teams are playing a 162-game season, a good approximation to the sampling standard deviation for an average team is 




Morris shows that the posterior mean of the true winning fraction is a compromise between the observed winning fraction

where 

Actually we are most interested in predicting the team’s fraction in the following season
Morris shows that this predictive density is normal with mean 

What is the chance that the team declines (in winning fraction) the following season? To answer this question, we look at the predictive density of the change in winning fractions 

Shiny App
I wrote a short Shiny app PredictWinningFraction() to illustrate these calculations. A snapshot of the app is displayed below. Since I think it is easier to think about quantiles, one input in this app are the prior quartiles of 

which means the posterior mean of

From the table, the predictive density of
How Do the Division Winners Perform the Following Season?
In MLB, using the Lahman package, I collected the winning fraction and the winning fraction in the following season for all division winners from 1969 through 2021. For the 265 division winners, the proportion that had a lower winning fraction the following season was 0.751. The average drop in winning fraction was 0.0435.
I next applied Morris’ model. Using each division winner’s winning fraction, I applied the Bayesian model with Morris’ average team prior and computed the probability of dropping in winning fraction in the following season and the mean drop size. I averaged these computations over the 265 division winners — I found the average probability of dropping in the next season to be 0.745 and the average drop size to be 0.0343. Note that the average drop probability 0.745 from this Bayesian model agrees closely with the actual observed drop fraction of 0.751, but the average drop size of 0.0343 from the model underestimates the observed average drop of 0.0435.
Comments
- (Morris’ article). In the article, Carl Morris is reviewing the baseball examples (such as the famous Efron and Morris example of simultaneously estimating 18 batting averages) that illustrate multilevel modeling. He used this division winner example to demonstrate the notion of Bayesian shrinkage. It is a relatively simple example of the two-stage Bayesian model that uses familiar data to a baseball fan.
- (Assumptions in the Bayesian model). There are two key assumptions in the Bayesian model. One is that the strength of the team doesn’t change between the two seasons, and a second is the prior mean that the division-winning team is average. One could use the Shiny app with a prior that reflects the belief that the team is above-average where the prior mean exceeds 0.50. But it is interesting that this use of this average team prior leads to the predictive calculation that 74.5% of the teams will experience a drop in the second season which agrees with the observed percentage drop among the 265 division winners in baseball history.
- (Shiny code?). The code for this Shiny app
PredictWinningFraction()is available as part of my ShinyBaseball package. The app is self-contained, so the interested user can try it out by downloading the singleapp.Rfile and placing it in a new folder, launching theapp.Rfile in RStudio, and running the app by use of therunApp()function.

Recent Comments