Constructing a Prior for Lindor’s Hit Probability
Introduction
As the reader probably knows, I am a Bayesian statistician and have illustrated Bayesian thinking for a number of posts over the years of this blog. I’m thinking of collecting many of my Bayesian posts into a “Bayesball” book. In doing this, I realized that I have written little on the process of constructing a subjective prior. After all, one advantage of a Bayesian perspective is the ability to input subjective belief or prior information into the inference process. This seems especially relevant for baseball problems where one has collected many measures of performance for players and certainly has opinions about players’ abilities.
This post illustrates the process of constructing a beta prior that reflecting my beliefs about a player’s hitting ability. We focus on learning about the 2021 hitting probability for the great shortstop Francisco Lindor. We have relevant information on his hitting performance during the seasons with the Indians. We use this information to construct a prior, at the start of the 2021 season, for his hitting probability. We update this prior with data for the first few months of the 2021 season, obtaining a posterior. This posterior will be used to predict Lindor’s batting average for the remainder of the season.
In this exercise, I’ll illustrate the use of one of my Shiny apps that facilitates learning about a proportion using a beta prior.
The Prediction Problem
One of the recent big free-agent signings in Major League Baseball was Francisco Lindor who signed a 10-year contract with the New York Mets starting with the 2021 season. Through the games of June 27, 2021, Lindor has had a relatively poor hitting season with 58 hits in 265 at-bats for a 58/265 = 0.219 batting average. We are interested in predicting Lindor’s batting average for the remainder of the 2021 season.
We illustrate the use of a subjective prior on Lindor’s true 2021 batting average p.
- We use Lindor’s batting record for his first six seasons to construct a beta prior for p.
- We update our beliefs about p by using Lindor’s batting performance in the first part of the 2021 season.
- We use the current beliefs about p to construct a prediction interval for Lindor’s future performance in 2021.
It will be helpful to use a Shiny app in this process that can be found at
https://bayesball.shinyapps.io/ChooseBetaNew2/
Lindor’s Batting Record
We want to construct a prior for p, Lindor’s hitting probability for the 2021 season. We have relevant information, specifically Lindor’s batting performance for the 2015 through 2020 seasons. Below we display the number of at-bats (AB), hits (H) for these seasons.
## Year AB H BA
## <dbl> <dbl> <dbl> <dbl>
## 1 2015 390 122 0.313
## 2 2016 604 182 0.301
## 3 2017 651 178 0.273
## 4 2018 661 183 0.277
## 5 2019 598 170 0.284
## 6 2020 236 61 0.258
The batting averages AVG = H / AB are not hitting probabilities, but represent Lindor’s hitting performances for these six seasons. But we can construct interval estimates for the hitting probabilities for the respective seasons. A standard 95% interval estimate for a probability has the form
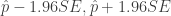
where 
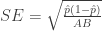
(By the way, these intervals are approximately Bayesian 95% probability intervals using a weakly informative prior.) I display the 95% bounds for the hitting probabilities against the season in the following graph. By looking at this graph, one see plausible values of the hitting probability for each season.

What do we see from this graph?
- Lindor’s best seasons with respect to batting average were in the initial 2015 and 2016 seasons.
- In 2017 through 2019, Lindor’s BA was pretty consistent between 0.277 and 0.284.
- In 2020, Lindor had his smallest BA of 0.258, but we have less confidence in the value of the corresponding hitting probability since it was based on only 236 AB.
Specify Parameter Values of the Beta Prior
We wish to construct a beta(a, b) prior for Lindor’s hitting probability p for the 2021 season. It is difficult to directly specify the beta shape parameters a and b of this prior. It is helpful instead to specify values of η and K where
a = K η, b = K (1 − η).
- We first specify η, the prior mean for p. I place more weight on Lindor’s performance during the two most recent full seasons 2018 and 2019. So I specify that η = 0.280. (In other words, we think that Lindor is a “.280 hitter” during the 2021 season.)
- The parameter K is reflective of the sureness of my prior guess that p is equal to 0.280. If I choose a larger value of K, the hitting probability is more likely to be close to 0.280.
The Shiny app is helpful in determining a reasonable choice for K. In the app, by use of sliders I choose the mean value η and the precision value K. The top graph shows the selected beta prior and displays a 90% interval estimate for the hitting probability p. (See the app snapshot below.) I choose a value for K that gives a plausible interval estimate for p. After some trial and error, I am comfortable with the 90% interval estimate (0.244, 0.318) that corresponds to a beta prior where η = 0.280 and K = 400.

Update with 2021 Data
Using data from the 2015 to 2020 seasons, I have constructed a beta prior with η = 0.280 and K = 400. The corresponding shape parameter values of the beta curve are
a = K η = 400 (0.280) = 112, b = K (1 − η) = 400 (1 − 0.280) = 288.
Now I observe 2021 hitting data for Lindor – he has 58 hits in 265 AB. Equivalently, he has 58 successes (hits) and 265 – 58 = 207 failures (outs).
One obtains the beta shape parameters for the posterior by simply adding the prior shape parameters to the numbers of successes and failures.
a1 = 112 + 58 = 170, b1 = 288 + 207 = 495.
The posterior mean is η1 = 170 / (170 + 495) = 0.256 and the posterior precision parameter is K1 = 170 + 495 = 665.
Prediction
One we have established that the posterior distribution for pp is beta(170, 495), it is straightforward to make predictions for Lindor’s hitting for the remainder of the 2021 season by use of the posterior predictive distribution.
We can use our Shiny app to obtain a prediction interval. By using the sliders, we select the beta parameters η = 0.256 and K = 665. We have to choose the number of at-bats for Lindor the remainder of the season. Lindor is an everyday player – he has currently averaged 265 / 72 = 3.68 AB in the Mets’ first 72 games. If we assume the same per-game AB for the Mets’ 89 remaining games, Lindor would have 89 (3.68 ) = 328 remaining at-bats. So we select 328 AB for the size of the future sample.

There are two graphs in the app.
- The top graph displays the posterior density for Lindor’s 2021 hitting probability p. From the posterior, we are 90% confident that his hitting probability is between 0.228 and 0.283.
- The bottom graph displays the predictive distribution for Lindor’s BA in the remaining part of the 2021 season. The 90% prediction interval for his BA is (0.207, 0.302). The probability this interval contains the future BA is 90%.
Comments
- A Bayesian analysis allows one to input expert knowledge by the use of a prior density. The process of actually constructing a prior is challenging since most of us have little practice doing it. Choosing a beta density to reflect beliefs about the location of a probability is relatively simple, but this activity can give one experience in constructing priors for more sophisticated problems.
- As the Shiny app shows, a prior or posterior has an associated predictive distribution for future data. For example, the last Shiny snapshot shows the posterior of the hitting probability and the implied (posterior) predictive distribution. Note that the predictive distribution is much wider than the posterior — for example, the 90% prediction interval estimate of the future BA is (.207, .302) which is wider than the 90% interval estimate for the true hitting probability. Predictive densities are wider since they incorporate two types of uncertainty — the uncertainty in the value of the hitting probability and the uncertainty in the observed BA given the hitting probability.

Recent Comments