Who Hit Best Against Roger Clemens?
Introduction
A few years ago, I wrote a post exploring batter-pitcher matchups, how batters perform against a specific pitcher and how pitchers perform against a specific batter. As an example in my earlier post, I displayed a plot showing the batting averages of all hitters who faced Jamie Moyer during his career. This plot showed the large variability (or as Bill James would say, dense fog) in batting measures for small samples. I illustrated the use of a multilevel (random effects) model to smooth these raw batting averages. These smoothed measures are straightforward to compute and one can use them to make some meaningful comparisons of hitters.
Since Tom Tango doesn’t want to talk about batting averages, I thought I’d generalize the earlier post by considering a better measure of batting performance such as wOBA. Also, I’ll use this post to illustrate the use of a Shiny app to display the smoothed estimates of wOBA where one selects an opposing single pitcher or single batter of interest. Using this smoothed estimates, one can actually answer the question: Who hit best and worst against Roger Clemens?
Raw wOBA Values Are Variable
Here is an illustration of the issue. Below I am graphing the wOBA measure against the number of plate appearances (PA) for all batters who faced Roger Clemens during his career. Note the high variability for small PA values — some hitters had wOBA values of 0 and 1.4 against Clemens. But these values don’t reflect their wOBA abilities against Clemens — it is desirable to smooth or adjust these extreme wOBA values towards an average to get better predictions of future performance. We certainly can’t say that the hitter with a 1.4 wOBA on a few PA is the best hitter against Clemens.

Multilevel Estimates of wOBA
To compute the wOBA measure, one assigns a weight to each of the PA outcomes and computes the mean of these weights. A hitter’s wOBA is basically a mean weight that is assumed to be normally distributed with mean M and standard deviation 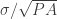


I use a Laplace-type approximation (available in the LearnBayes package) to quickly fit this multilevel model. This fit provides estimates of mu, tau and
(observed wOBA) x weight + (average wOBA) x (1 – weight),
where weight is a fraction between 0 and 1. Basically the estimate at a player’s true wOBA is a weighted average of the observed wOBA and the overall wOBA against Clemens. Here is a graph comparing the raw and multilevel estimates of wOBA — we see the strong shrinkage towards the average especially for hitters with small PA values.

The Shiny App
I wrote a Shiny app wOBA_Matchups to explore the smoothed wOBAs.
- First decide on the Matchup Type — is one interested in matchups against a specific batter or matchups against a specific pitcher? I chose Pitcher in the example below.
- Next Select a Pitcher from the dropdown menu containing the leading pitchers (in terms of PAs) during the 1960-2021 era. I chose Roger Clemens from this list.
- Decide on the Plot Type — here I chose Multilevel. (If one chooses Comparison as the Plot Type you will see the plot above comparing the two wOBA estimates.)
We see a scatterplot of the wOBA estimates against the plate appearances. The table on the left shows the multilevel estimates — here mu est = 0.274 and tau est = 0.054. The estimate of mu represents an average wOBA against Clemens and the estimate of tau controls the size of the adjustment of the observed wOBA towards the average wOBA.

Several takeaways from looking at this graph:
- Note that for small PA the observed wOBA values are adjusted strongly towards the average value of 0.274. This makes sense — we don’t have much information about these batters with small PA values and so our prediction is close to the average wOBA.
- In contrast, the adjustment of the observed wOBAs towards the mean is smaller for batters with large PAs against Clemens.
- One compares players by comparing their wOBA estimates. Who batted best against Clemens? The app allows one to use a brushing rectangle to identify interesting points and measurements about the selected players are displayed at the bottom. In the screenshot, using a blue rectangle I have identified six players (Ken Griffey, Rafael Palmeiro, Jim Thome, Alan Trammell, Lou Whitaker) with large wOBA estimates and high number of PAs.
- One player does stand out as best — the HOF player Jim Thome had an adjusted wOBA of 0.412 against Clemens which is 40 points higher than any other hitter. (By the way, Baseball Roundtable in its “Who’s Your Daddy” series identified Thome as a hitter unusually successful against Clemens.)
- It is interesting that the players with large PAs tended to do better than average against Clemens. (I guess it is reasonable to batters with more experience against Clemens would hit better than average.)
Matchups Against a Specific Batter
Using this app, we can instead choose matchups against Batter and see the wOBA performances of all pitchers against a batter of interest. For example, here is a graph of the wOBA estimates of the 1362 pitchers who faced Derek Jeter during his career. There is one noteworthy low pitcher performance — when we select that one point, we see that Jeter struggled against the HOF pitcher Roy Halladay. Jeter’s observed and estimated wOBA values against Halladay were 0.257 and 0.318, respectively.

Closing Comments
- Noisy Data. As said in my earlier post on matchup data, most of the variability in wOBAs for hitters against a specific pitcher (or pitchers against a specific hitter) is noise, that is, not meaningful. But there are small variations in true wOBA among the players and one gets a handle on this small signal by means of this multilevel model.
- Reversals. One sees some interesting reversals where the ordering in the estimated wOBAs differs from the ordering in the observed wOBAs. In our first example, Rafael Palmeiro has a lower observed wOBA value (.399) than Alan Trammell (.416), but Palmerio’s estimated wOBA (.354) is higher than that for Trammell (.348). The reason for this reversal is that we’re more confident of Palmeiro’s .399 value since it is based on more PA — Palmeiro’s observed wOBA is adjusted less towards the mean.
- Try Out the App! I have uploaded this Shiny app to the RStudio server, so you can try out the live version at https://bayesball.shinyapps.io/wOBA_Matchups/
- Got Code? If you’d like to improve this app, you can download the single app.R file from the ShinyBaseball package. You don’t need any additional data since all data is retrieved from Github. The only special packages that you need to install from CRAN are the Lahman and LearnBayes packages. (The interested reader likely has the readr, dplyr, ggplot2 and shiny packages already installed.)
- Data Issues. You might notice that the dropdown menu contains a relatively small number of players. I did this to make the size of the underlying play-by-play dataset relatively small. If you look at all PA plays for the seasons 1960 through 2021 from the Retrosheet files, you have a data frame with almost 10 million rows! By restricting to a small number of batters and pitchers with large numbers of PA, I reduce the data frame to only 588,231 rows, and I could upload this data to my Github site.
- Related Posts. I have already mentioned a 2015 post where I discuss batter-pitcher matchups for batting averages. In a 2019 post, I explored pitcher-batter matchups for home run rates. In this 2019 post, I fit a non-nested random effects model to home run stats for all batters and all pitchers.

Recent Comments