Pitcher/Batter HR Match Ups and the Shrinking Standard Deviation
Introduction
I’ve been thinking about home runs too much in 2019, and based on our recent MLB report, it appears that I will continue to explore home runs in 2020. Here is an interesting thing about home run production. We all know that there have been a record number of home runs hit in recent seasons (6776 home runs hit in 2019). But we haven’t observed recent great individual home run achievements. For example, the only people to exceed Roger Maris’ (1961) season of 61 home runs are Barry Bonds, Sammy Sosa, and Mark McGwire, and all of these season home run records are tainted due to the Steroids era. (Here is a recent article on the effect of steroids on hitting performance.) So currently we are seeing great collective home run hitting, but we aren’t seeing this greatness at the individual level.
Also, the media gets excited about batter-pitcher match up stats. For example, in 2017, Max Kepler hit 5 home runs in 7 balls in play against Trevor Bauer and Jordan Luplow hit 4 home runs in 6 BIP against Manny Banuelos. How does one make sense of these extreme accomplishments?
In this post, we’ll explore all batter-pitcher home run match ups for a particular season. By use of a random effects model, we’ll address these questions:
- If one looks at the variability of all of the home run rates, how much of this variability is due to differences between batters and how much is due to differences between pitchers?
- This model fitting will allow us to measure the variability of home run rates among batters and the variability of the rates among pitchers. How have these measures of variation changed in the last 20 seasons?
A Disclaimer
Typically when I start thinking about a new post I check to see if I’ve posted on the same topic in the past. Unfortunately, I didn’t do that in this case. A couple of years ago, I posted on home run rates and fit the same model. But this post complements what I did earlier and provides some new insight here, specifically in looking at the model fits for the last 20 seasons.
The Data
For a particular season, say 2019, I use Retrosheet play-by-play data to collect the number of balls in play and the number of home runs hit for each batter against each pitcher. There were 62,409 of these match ups in the 2019 season. In the following graph, I plot the number of balls in play (horizontal) against the home run rate (vertical) for all of these matchups. Since there is serious overplotting, I jitter the point location so one can guess at the number of matchups at a particular location. Also I color the plotting point by the number of home runs. For most matchups, there were 0, 1, or 2 home runs hit. But there were 25 occurrences where a batter hit 3 home runs against a specific pitcher, and as noted above, there was one 5 home run occurrence (Kepler against Bauer) and one 4 home run occurrence (Luplow against Banuelos).

A Random Effects Model
A random effects model is a helpful way of understanding the sources of variation of these home run rates — how much is due to pitchers and how much is due to the batters. Since we are used to thinking about home run sluggers and less about pitchers who allow a lot of home runs, I think one would think that the greatest source of variability would be the hitters, but we can check this by fitting the model.
Let 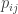

To complete the model, we assume that the batter effects {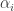
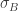

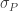
Fitting the Model to the 2019 Data
We fit this model quickly using the glmer() function from the lme4 package. When we fit this model to the 2019 season data, we obtain the estimates
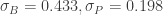
As we thought, much more of the variability in the home run rates is due to batters compared to pitchers. One way to demonstrate this is to graph the estimates of the batter effects and the pitcher effects (on the probability scale) on the same graph. We see that the the pitcher home run rate estimates are close to 0.05, but there is larger variation in the batter home run rate estimates.

Fitting the Model for Recent Seasons
Since there has been dramatic changes in home run hitting in recent seasons, I am interested in how the sources of variation of the home run rates have changed. So I fit this random effects model for each of the last 20 seasons from 2000 to 2019, collecting the values of
Here’s a plot of the pitcher standard deviations against season. It seems that there has been no obvious change in these standard deviation estimates, but we note one unusually low value in 2016.

When we plot the batter standard deviation estimates, we see a clear pattern. There is a steady drop in the batter standard deviation estimates from 2011 through 2019.

Takeaways
- I’ve written a single R function fit_model() (found on my gist Github site) that does all of these calculations. The input is a Retrosheet play-by-play data frame and the output is (1) the batter-pitcher matchup data, (2) the graph of these data, (3) the estimates of the random effects and (4) the estimates at the batter and pitcher standard deviations.
- As one would expect, this shows that most of the variability in the home run rates is due to differences in batters compared to differences in pitchers. So it makes sense to focus on home run leaders among batters.
- But batters are getting more similar in home run ability, as demonstrated by the decreasing value of the batter standard deviation. It is notable that the smallest value of the home run standard deviation was achieved in 2019.
- This is reminiscent of Stephen Jay Gould’s batting average study. Gould thought that we would never see a .400 batting average due to the decreasing standard deviation of the AVGs in recent seasons. In a similar fashion one might wonder if we will never again see a 70 home run season performance due to the shrinking standard deviation of the batter standard deviations.
- This is an interesting area of research which deserves further study. For example, one could use this random effects model to predict the home run production in future seasons. In particular, one could predict the leading home run count in 2020. Another question would be about these extreme match up stats (the 5 HR out of 7 BIP and the 4 HR out of 6 BIP instances from the 2019 season). Are these extreme stats unusual assuming our random effects model that does not include any interaction terms? One could use a predictive check to see what outliers are predicted from our model.

Recent Comments