What is a Batting Average?
I know most baseball analysts don’t like a batting average since it isn’t a helpful measure of batting performance. But I think a batting average can be useful if it is expressed into components that involve strikeouts, home runs, and getting a hit on a ball in play. Here I focus on learning about batters’ hitting abilities and use a random effects model to learn about the ability aspects of the components of batting average. In this exercise, I illustrate the use of a new R package ggdensity that provides useful graphical displays of bivariate data.
Components of Batting Average
Here is a decomposition of a batting average — using some algebra, one writes the batting average as

where
is the strikeout rate
is the rate of home runs on balls put into play
is the rate of hits on balls put into play in the ballpark
It is not helpful to talk about a player that “hits for average” since it is hard to understand the characteristics of the hitting talent that corresponds to, say, a .300 batting average. But I think it is advantageous to talk about batting ability using the components strikeout rate, home run rate, and BABIP. Strikeout rate relates to a player’s plate discipline and ability to make contact with the pitch and home run rate is a measure of a player’s slugging ability. One player might have a .320 batting average because he tends to put the ball in play (that is, a low strikeout rate) and has a high hit rate on balls put into play. In contrast, Aaron Judge’s current .310 average is likely a by-product of his high home run rate. We currently use slash stats (AVG / OBP / SLG) to describe a player’s hitting. Similarly it would seem reasonable to use another set of slash stats (SO.Rate / HR.Rate / BABIP) to describe the components of a player’s batting average.
Estimating Component Abilities
I collected the SO.Rate, HR.Rate and BABIP for each batter with at least 100 AB in the 2021 season. Let 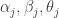

Each batter has three associated probabilities. I convert each probability to a logit — let 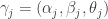



I fit this model to our 2021 season data. I won’t go into the details of the estimation procedure here. I used JAGS and the runjags package to fit this model by Markov chain Monte Carlo. Using the simulation output, I estimated the SO, HR and BABIP probabilities for all players.
Graphs
We compare the observed SO, HR and BABIP rates (on the logit scale) with the estimated logit probabilities for all players using the multilevel (random effects) model.
Here is where we are applying the ggdensity package. When one visualizes distributions of two variables, then standard contour maps, say using the geom_contour_filled() function in ggplot2, are pretty but hard to interpret. The ggdensity package offers an attractive alternative — the function geom_hdr() is a replacement for the ggplot2 function geom_contour_filled() that shows regions of highest probability content. By default, it will show one region containing 50% of the values, another region containing 80% of the values, and two larger regions showing respectively 95% and 99% of the values.
Here we use these new contour graphs to display side-by-side scatterplots of the observed strikeout and home run rates (right) and the estimated strikeout and home run probabilities (left). Note several interesting things:
- To interpret these contours, note that 50% of the rates occur within the yellow region and 80% of the rates fall within the green region.
- Comparing the Observed and Ability graphs, we see these fitted models for ability essentially shrink or adjust the observed rates towards the average. That is, the model estimates adjust the extreme home run rates and strikeout rates towards the average rates for all hitters.
- When one looks at the scatterplot of the observed rates (right graph), one sees a small positive relationship between the two rates. In contrast, there is a relatively strong positive association between the strikeout rate and the home run rate ability estimates (left graph). This means that batters who strike out a lot tend to hit home runs at a high rate.

Here are scatterplots of the observed and estimated SO and BABIP rates (first graph below) and the HR and BABIP rates (second graph below). Note that the BABIP ability estimates adjust the observed rates strongly towards the average. This is in contrast to what happens to the SO rates or the HR rates — for these rates there is a smaller adjustment of the observed rates towards the estimated ability rates. The takeway is that the strikeout rates and home run rates reflect the different player talents. In contrast, the differences in the observed BABIP rates reflect chance variation rather than meaningful differences in hitting abilities.


Using the Model to Predict
One use of this model is to predict future batting performance. For example, since this model was based on 2021 season data, one can predict strikeout rates, home run rates and BABIP rates for the 2022 season. Suppose you have a player with a low strikeout rate, low home run rate and a high BABIP rate in 2022. Looking in the future, since strikeout rates and home run rates are ability-driven measures, I would anticipate small changes in these rates in a future season. In contrast, since BABIP rates are chance-driven, I would anticipate the high BABIP rate in in 2021 to drop close to the average BABIP in 2022. These type of predictions would be made automatically by simulating draws from the posterior predictive distribution.
Closing Remarks
- Some years back I wrote a paper published in Journal of Quantitative Analysis of Sports on the estimation of batting average components. Since this journal has limited access, here is a arXiv version of the paper. The difference in the approach taken here is that I am assuming a multivariate normal prior on the component probabilities. This makes sense since I believe there is some positive association between a home run probability and a strikeout probability.
- I’ve written about these BA components in older posts. For example, here is a post where I focus on the the in-play rate 1 – SO / AB and the hit on all balls in play rate H / (AB – SO).
- The ggdensity package provides two useful functions
geom_hdr()andgeom_hdr_lines()that are easy to use (just replace theggplot2geoms with these functions) and provide helpful interpretation for paired data. In addition, for a Bayesian, they provide useful interpretations of bivariate distributions of two parameters from simulation output.

Excellent work. I’d be curious about developing this further by using OPS components instead of BA. First component plate discipline combining k rate and bb rate. Second power. Third BABIP. Possibly more components but idea being creating hitting profiles for lineup construction. And also in separating skill vs luck in performance evaluation